
Authors
Reza Qorbani*1, Gianluca Villani*2,3, Theodoros Panagiotakopoulos2, Marc Botet Colomer2, Linus Härenstam-Nielsen4,5, Mattia Segu2,6, Pier Luigi Dovesi2,7, Jussi Karlgren2,7, Daniel Cremers4,5, Federico Tombari5,8, Matteo Poggi9
(*joint first authors)
1KTH
2The Good AI Lab
3University of Toronto
4Technical University of Munich
5Munich Center for Machine Learning
6ETH Zurich
7AMD Silo AI
8Google Inc.
9University of Bologna
Abstract
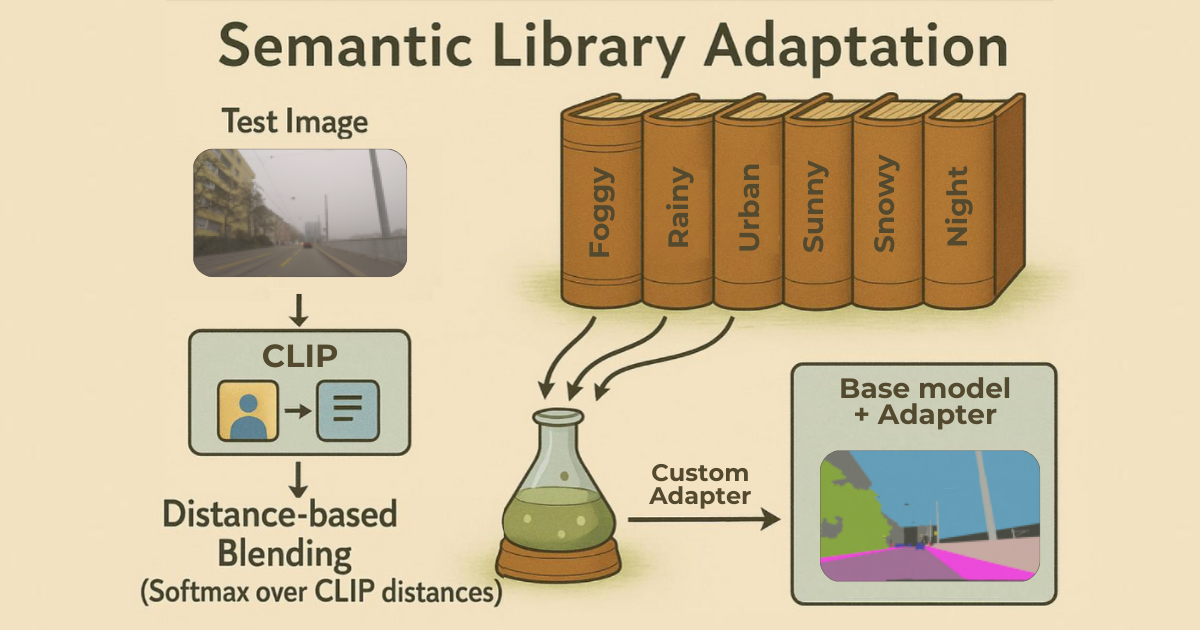
We introduce Semantic Library Adaptation (SemLA), a framework for training-free, test-time domain adaptation in open-vocabulary semantic segmentation, leveraging a library of Low-Rank Adaptation (LoRA) adapters. At test time, SemLA dynamically merges the most relevant adapters based on proximity to the target domain in the embedding space. Our method scales efficiently, enhances explainability by tracking adapter contributions, and inherently protects data privacy, making it ideal for sensitive applications.
Overview
Modern vision models are expected to perform well across wildly different domains—urban scenes, indoor environments, foggy nights, sunny highways, synthetic worlds. But in practice, models trained in one setting often fail in another. Fine-tuning helps, but it's expensive, slow, and usually requires access to labeled data that is not available. Open-vocabulary models promise flexibility, yet they rarely match the precision of task-specific fine-tuned models. And even if you've already invested in building a large library of adapters trained across various domains, you're left with a new challenge: when the next input image comes in, how do you decide which adapters to use—and how to combine them—without retraining anything?
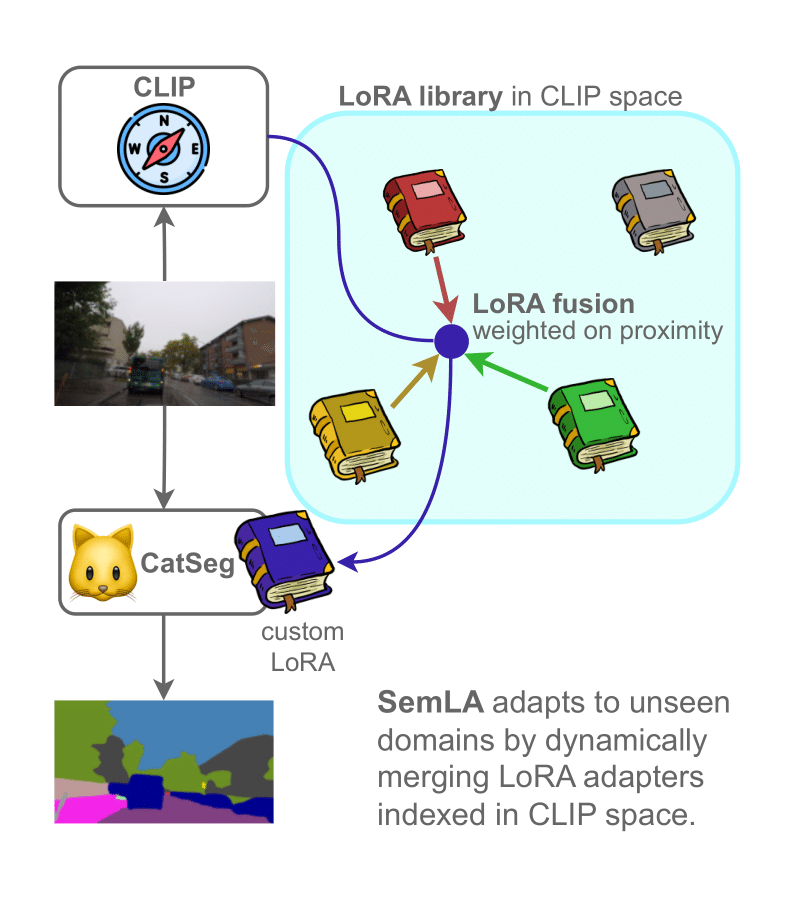
SemLA addresses this challenge by providing a framework for training-free, test-time domain adaptation. It leverages a library of Low-Rank Adaptation (LoRA) adapters, each specialized for different domains. At test time, SemLA dynamically selects and merges the most relevant adapters based on their proximity to the target domain in an embedding space. For example, imagine you need to segment foggy night images. Your library might not include an adapter explicitly trained on "foggy night" images, yet it likely contains adapters specialized for either "fog" or "night" conditions. SemLA addresses this by using CLIP embeddings to identify adapters whose training data is semantically similar to the input domain, then merging those adapters accordingly. This approach yields a customized segmentation model—instantly adapted to unknown domains. In addition to boosting adaptability, SemLA provides explainability. By tracking adapter contributions, it clarifies which adapters play the largest role in the final prediction. The approach also safeguards data privacy, since no retraining or direct access to the original data is required at test time. This makes SemLA particularly appealing for sensitive applications such as autonomous driving, or healthcare.
Building a LoRA Adapter Library
Building and maintaining a domain-specific LoRA Adapter Library follows a straightforward procedure:
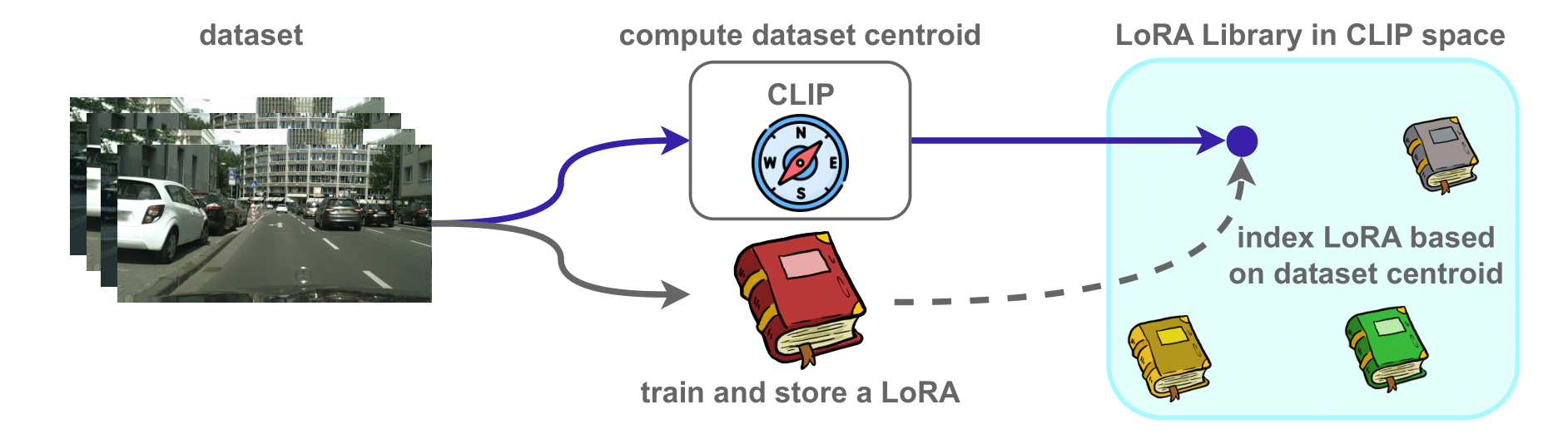
1. Create Domain Embeddings
For each labeled domain, we compute a representative CLIP embedding that serves as a "centroid" capturing the main characteristics of that domain's images.
2. Train Domain-Specific Adapters
We then fine-tune LoRA parameters for each domain while keeping the base model frozen. Each adapter is associated with its corresponding domain centroid.
3. Assemble the Library
These domain centroids and their corresponding LoRA adapters are collected into a unified repository, creating the foundation for dynamic adapter selection and merging at test time.
4. Continuously Expand
The library naturally grows whenever new labeled data becomes available. For each new domain, we generate its embedding, train a new adapter, and add both to the library. This ongoing process ensures the system evolves to handle an ever-expanding range of domains.
Citation
@inproceedings{qorbani2025semla,
author = {Qorbani, Reza and Villani, Gianluca and Panagiotakopoulos, Theodoros and Botet Colomer, Marc and H{\"a}renstam-Nielsen, Linus and Segu, Mattia and Dovesi, Pier Luigi and Karlgren, Jussi and Cremers, Daniel and Tombari, Federico and Poggi, Matteo},
title = {Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2025}
}Acknowledgements
The authors thank Hedvig Kjellström for the helpful discussions and guidance, and acknowledge the European High Performance Computing Joint Undertaking (EuroHPC JU), EuroCC National Competence Center Sweden (ENCCS), and the CINECA award under the ISCRA initiative for the availability of high-performance computing resources and support.
This study was funded by the European Union – Next Generation EU within the framework of the National Recovery and Resilience Plan (NRRP) – Mission 4 "Education and Research" – Component 2 – Investment 1.1 "National Research Program and Projects of Significant National Interest Fund (PRIN)" (Call D.D. MUR n. 104/2022) – PRIN2022 – Project reference: "RiverWatch: a citizen-science approach to river pollution monitoring" (ID: 2022MMBA8X, CUP: J53D23002260006).