
Lost in Translation? Vocabulary Alignment for Source-Free Adaptation in Open-Vocabulary Semantic Segmentation
VocAlign: A framework for source-free domain adaptation in open-vocabulary segmentation
Authors
Silvio Mazzucco1,2*, Carl Persson1*, Mattia Segu1,2,3, Pier Luigi Dovesi1, Federico Tombari3,4, Luc Van Gool5, Matteo Poggi1,6
(*joint first authors)
1The Good AI Lab
2ETH Zurich
3Google
4Technical University of Munich
5INSAIT, Sofia University
6University of Bologna
Vision-Language Models (VLMs) have recently opened the door to open-vocabulary semantic segmentation – the ability to label every pixel in an image, even with classes the model has never explicitly seen during training. This is powerful, but it comes with a challenge: when these models are deployed in new environments, their performance often drops sharply. Why? Because the "language" of categories used during training does not always align with the vocabulary of the new domain – think of a "wall" in CityScapes vs. a "building wall" in COCO.
Traditionally, domain adaptation methods fix this by accessing the original training data. But for VLMs trained on huge, proprietary datasets, that's not possible. This is where our work comes in.
Our contribution: VocAlign
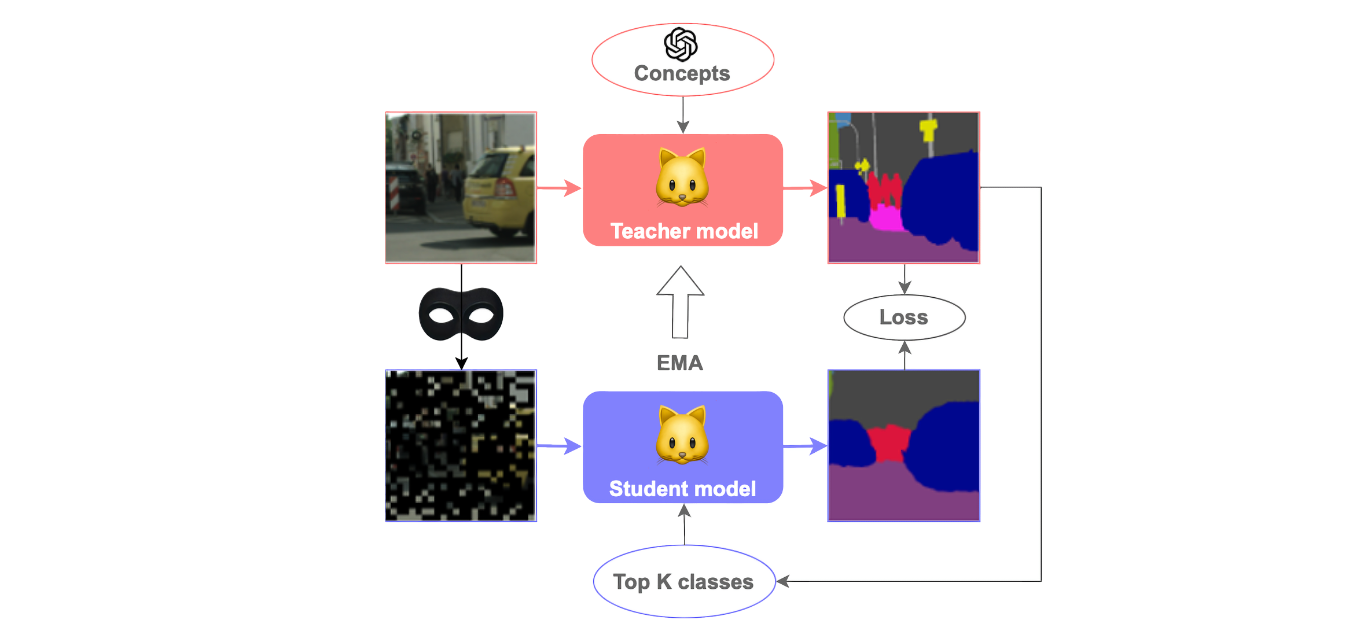
We introduce VocAlign, the first framework for source-free domain adaptation in open-vocabulary segmentation. Instead of relying on inaccessible source data, we adapt the model directly to its new environment through three key ideas:
-
Vocabulary Alignment
Enrich the model's vocabulary with additional concepts and synonyms, aligning the teacher's "language" with the target domain. This improves pseudo-labels and helps recover classes that would otherwise be misinterpreted. -
Efficiency via LoRA
Adapt large VLMs using lightweight Low-Rank Adaptation (LoRA) modules, keeping compute overhead low while preserving the broad knowledge from pretraining. -
Top-K Class Selection
Focus on only the most relevant classes per image rather than all classes at once. This reduces memory needs and surprisingly improves adaptation by reinforcing the strongest signals.
Why it matters
VocAlign bridges a critical gap: it allows VLMs to adapt to new domains without source data, without prohibitive compute, and without sacrificing their open-vocabulary flexibility. On benchmarks like CityScapes, VocAlign improves performance by over +6 mIoU, fully recovering previously unrecognizable classes such as "terrain" or "wall". It also generalizes to diverse datasets like ADE20K and Pascal Context, showing consistent gains.
Key Takeaway
Models often get lost in translation when moving between domains. VocAlign provides them with a richer dictionary and a more efficient adaptation path, setting a new standard for source-free adaptation in open-vocabulary segmentation.
Acknowledgments
We acknowledge the European High Performance Computing Joint Undertaking (EuroHPC JU), EuroCC National Competence Center Sweden (ENCCS) and the CINECA award under the ISCRA initiative for the availability of high-performance computing resources and support.